
SysNucleus WebHarvy stands as a revolutionary tool in data extraction, empowering users with an intuitive, point-and-click interface to gather data from various websites effortlessly. Unlike traditional web scraping techniques that demand coding expertise, WebHarvy eliminates the need for programming skills, making it accessible to a broad spectrum of users.
SysNucleus WebHarvy's visual interface simplifies the web scraping process, transforming it into a seamless experience. With a mere click, users can identify and select the desired data elements from any website, regardless of their complexity. This visual approach eliminates the complexities of underlying HTML structure, enabling users to focus on the data they seek.
SysNucleus WebHarvy's remarkable adaptability extends to handling various data extraction scenarios. Whether extracting data from multiple pages via pagination links or navigating through websites with infinite scroll functionality, WebHarvy seamlessly handles these intricacies. Moreover, it safeguards data integrity by enabling anonymous scraping through proxy servers or VPNs, ensuring compliance with website terms and conditions.
With its comprehensive feature set, SysNucleus WebHarvy caters to a wide range of data extraction needs. From extracting product listings from eCommerce platforms to gathering property details from real estate websites, WebHarvy effortlessly tackles a diverse array of tasks. Its ability to extract images, text, HTML, email addresses, URLs, and more ensures that users have access to the precise data they require.
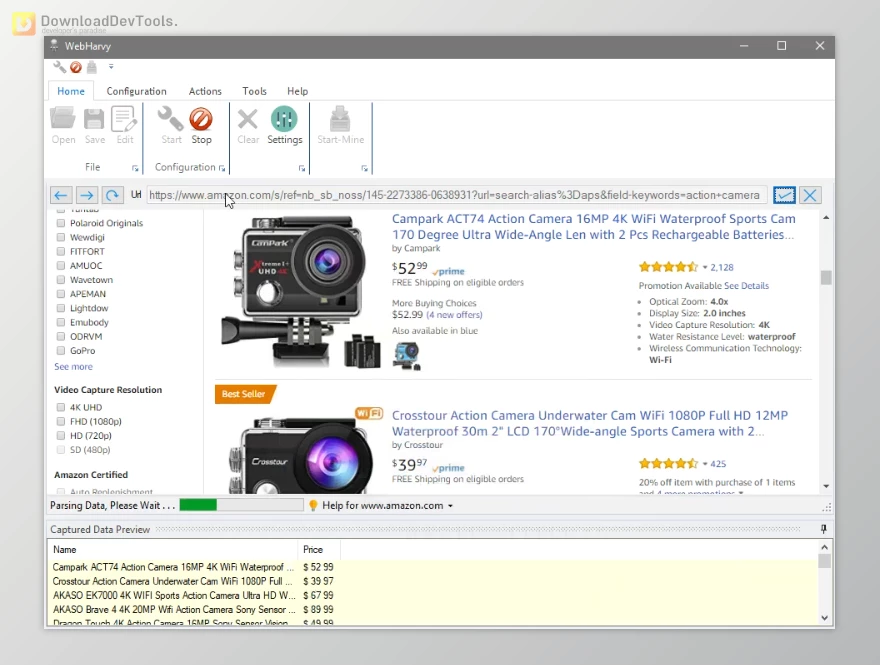
Key Features of SysNucleus WebHarvy :
-
Efficiently navigate web pages: Automate browser actions like form submission, search, and clicks to seamlessly navigate to the desired data extraction point.
-
Streamline login processes: Automate logging into websites, saving time and effort.
-
Leverage pagination to extract data: Seamlessly crawl through multiple pages of website content by following pagination links, gathering the desired data from each page.
-
Harness infinite scroll data: Successfully extract data from pages that utilize infinite scrolling, where content loads dynamically as the user scrolls down.
-
Maintain anonymity while scraping: Prioritize data privacy by employing proxy servers, VPNs, and human emulation techniques to prevent detection and maintain anonymity.
-
Automate data extraction across categories: Automatically gather data from multiple subcategories within a website, streamlining the data collection process.
-
Perform parallel extraction: Optimize data extraction by simultaneously processing multiple webpages, enhancing efficiency and reducing overall processing time.
-
Extract diverse data formats: Seamlessly extract various data types, including images, text, HTML code, email addresses, and URLs, ensuring comprehensive data collection.
-
Conduct keyword-based searches: Efficiently search for and extract relevant data from search results for a specified list of keywords.
Click on the links below to Download the latest version of SysNucleus WebHarvy with CRACK !
- OLD (0 B - 7/3/2026 1:53:55 AM)
 SysNucleus WebHarvy v7.11.0.248 (20 Feb 2026) + Patch.rar (Size: 154.8 MB - Date: 2/21/2026 1:00:37 PM)
SysNucleus WebHarvy v7.11.0.248 (20 Feb 2026) + Patch.rar (Size: 154.8 MB - Date: 2/21/2026 1:00:37 PM)- SysNucleus WebHarvy v7.9.0.246 (09 Jan 2026) + CRACK & Patch.rar (Size: 154.8 MB - Date: 1/28/2026 12:26:13 PM)
- SysNucleus WebHarvy v7.9.0.245 (27 Nov 2025) + Patch.rar (Size: 154.8 MB - Date: 12/1/2025 11:02:11 AM)
Files Password : DownloadDevTools.ir
Note
Download speed is limited, for download with higher speed (2X) please register on the site and for download with MAXIMUM speed please join to our VIP plans.
Discover free tools, limited-time offers, and stay updated with the latest software we release.
















12/28/2022 12:45:53 PM
Please upload latest version Webharvy 6.6.0.198