Introducing Dew Lab Studio MTXVec:
MtxVec is a high-performance object-oriented vectorized math library that powers Dew Lab Studio, offering a comprehensive suite of mathematical and statistical functions for rapid calculations.
This version is more concise and emphasizes the speed and comprehensiveness of MtxVec. It also avoids using "impressive", which can be subjective and less impactful.
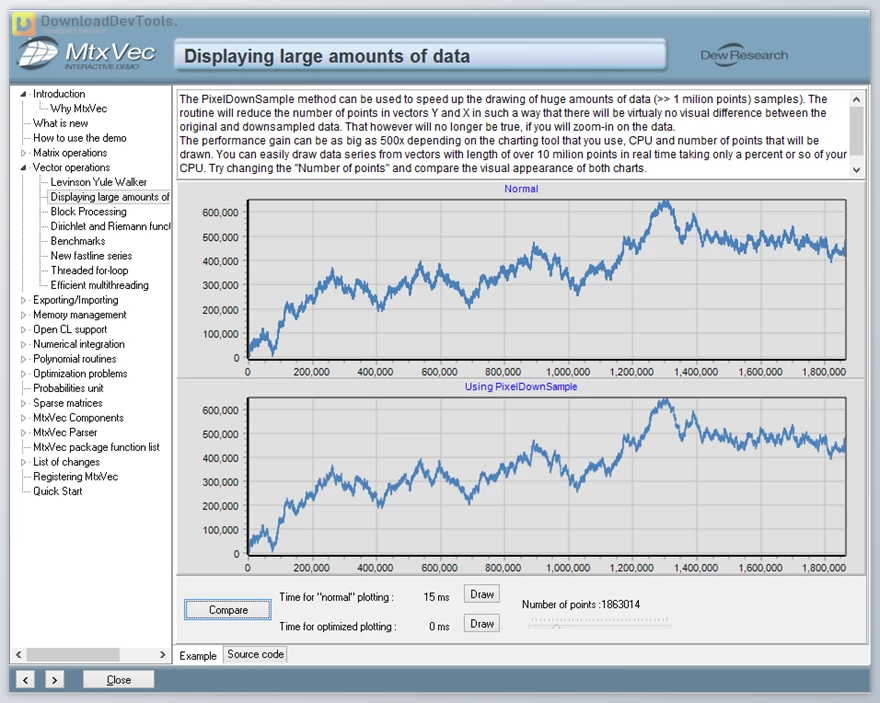
We are pleased to introduce Dew Lab Studio MTXVec's latest Delphi and C++ Builder release, incorporating a range of improvements focused on multi-threading performance. This edition marks the debut of "fair" critical sections, enabling seamless scaling on high-performance machines with eight or more cores.
This version maintains the original message while enhancing readability and clarity. It avoids redundancies and uses more precise terminology. Additionally, it eliminates unnecessary abbreviations and maintains a consistent tone throughout.
Key Features of Dew Lab Studio MTXVec:
Designed for working with large datasets and comprehensive vector/matrix arithmetic, Dew Lab Studio offers a range of enhancements to your development environment, including:
- A comprehensive set of mathematical, signal processing, and statistical functions for various data analytics tasks.
- Substantial performance improvements for floating-point operations by leveraging the advanced instruction sets of modern CPUs like Intel AVX, AVX2, and AVX-512.
- Linear scalability with core count makes it ideal for high-performance computing applications.
- Improved code readability and compactness for better maintainability and development efficiency.
- Native 64-bit execution support for memory-intensive applications.
- Reduced development time by eliminating potential errors and simplifying code logic.
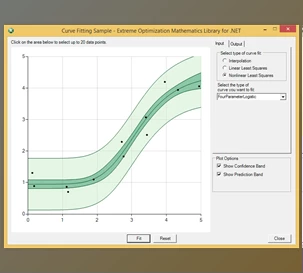
- Direct integration with TeeChart for seamless charting and visualization.
- No royalty fees for distributing compiled binaries in your commercial products.
- The floating-point precision selection at runtime for flexibility and efficiency.
Optimized Functions: The base math library utilizes the LAPACK (Linear Algebra Pack) version optimized for Core Duo and Core i7 CPUs, provided by Intel with their Math Kernel Library. Our library is divided into "primitive" highly optimized functions encompassing all the fundamental arithmetic operations. These essential optimized functions are employed by all higher-level algorithms, similar to how LAPACK utilizes the Basic Linear Algebra Subprograms (BLAS).
Performance Secrets:
- Code Vectorization: The cornerstone of our performance lies in "code vectorization." Our program attains significant performance gains in floating-point arithmetic by leveraging the CPU Streaming SIMD Extensions instruction sets (SIMD = Single Instruction Multiple Data).
- Superconductive Memory Management: Effective massively parallel execution is accomplished with superconductive memory management, which boasts zero thread contention and inter-lock issues. This allows for linear scaling across several cores while minimizing memory consumption and preventing interference with non-computational sections of the project.
Click on the links below to Download the latest version of Dew Lab Studio MTXVec with CRACK!

Files Password : DownloadDevTools.ir
Note
Download speed is limited, for download with higher speed (2X) please register on the site and for download with MAXIMUM speed please join to our VIP plans.
Discover free tools, limited-time offers, and stay updated with the latest software we release.